Overview
Jobs are blueprints that define when, how, and what browser automations to execute. Instead of triggering individual API runs manually, Jobs allow you to orchestrate multiple automation executions together - whether running them in bulk, on a schedule, or both. Think of Jobs as batch processing for your browser automations. Jobs solve the challenge of coordinating multiple automation runs at scale. When you need to scrape hundreds of product pages, process a list of accounts, or run periodic data collection tasks, Jobs provide the infrastructure to execute these operations reliably. They handle scheduling, retries, concurrency management, and result aggregation, so you can focus on building your automations rather than managing their execution. You would use Jobs when you need to execute browser automations in bulk (processing multiple inputs at once), run automations on a recurring schedule (hourly data collection, daily reports), coordinate multiple related API calls together. Jobs are particularly valuable when you need visibility into batch execution progress and want to send aggregated results to external systems via webhooks or S3.How It Works
Jobs operate as templates that define execution patterns. When you create a Job, you specify four key components: the payload (which APIs to run and with what parameters), the configuration (retry policies and concurrency limits), an optional schedule (when to run automatically), and an optional sink (where to send results). Each time a Job executes - either triggered manually or by its schedule - it creates a JobRun, which is a specific instance of that Job’s execution. A single JobRun processes all payload items defined in the Job, creating individual Runs for each API call. Each Run may involve multiple Attempts if retries are needed.Authentication Support
Jobs have first-class support for authenticated browser automations. When your Project has authentication enabled, Jobs can execute all their Runs using a shared AuthSession, making it seamless to run authenticated scraping or automation tasks at scale. The authentication model for Jobs implements a two-tier validation approach:- Job-Level Validation: When a JobRun starts, it validates the AuthSession once and handles recreation if needed
- Run-Level Validation: Each Run within the JobRun still validates the AuthSession before every Attempt, ensuring no API executes with an expired session
Nested Scheduling
Jobs support nested scheduling, a powerful pattern where an API can dynamically expand the JobRun’s payload during execution using theextendPayload function. This allows one API to discover work for other APIs to perform as part of the same JobRun.
The workflow operates as follows: an initial API Run executes and determines additional work needed, calls extendPayload to add new payload items to the active JobRun, and the JobRun automatically executes these newly added items. This is particularly useful for scenarios where the full scope of work isn’t known until you start executing.
A common use case is dynamic web scraping. Consider scraping an e-commerce site where product URLs aren’t known upfront:
- First API: navigates to category pages and extracts all product URLs
- Uses
extendPayloadto add a new API call for each product URL discovered - Extended APIs: scrape individual product details from each URL
Configuration
Jobs are defined as JSON configurations that can be created and managed through the Intuned UI (Jobs tab in your Project) or programmatically via the Jobs API.Basic Job Structure
Every Job requires an ID, description, and payload. Here’s a minimal example:Payload Configuration
Thepayload array defines what APIs to execute. Each payload item specifies:
apiName: The name of the API to run (must exist in your Project)parameters: An object containing the parameters to pass to the APIretry(optional): Override the Job-level retry setting for this specific payload item
Execution Configuration
Theconfiguration object controls retry behavior and concurrency:
maximumAttempts: Default maximum attempts for each payload item (default: 3)maximumConcurrentRequests: Maximum payload items executing simultaneously (default: max concurrent requests set in your Project Intuned.json)requestTimeout: Maximum time in seconds to wait for each Run attempt before considering it failed (default: 600 seconds)
Schedule Configuration
Add aschedule to run Jobs automatically. Jobs support two scheduling methods:
Intervals - Run every X period:
- Single values:
"hour": 9 - Ranges:
"hour": { "start": 9, "end": 17 } - Wildcards:
"month": "*"(every month) - Day names:
MONDAY,TUESDAY, etc.
Jobs trigger when any interval or calendar condition is met. If you configure both “every 7 days” and “first of every month”, the Job runs when either condition occurs.
AuthSession Configuration (For Authenticated Projects)
If your Project has authentication enabled, every Job must specify anauth_session that all Runs within the JobRun will use. You can also configure automatic session recreation behavior at the Job level.
id(required): The ID of a credential based AuthSession to use for all Runs in this JobcheckAttempts(optional): Number of times to validate the AuthSession before each Run attempt (default: 3)createAttempts(optional): Number of times to recreate the AuthSession if invalid (default: 3)
For detailed information about AuthSessions, authentication patterns, credential management, and advanced authentication scenarios, see the AuthSessions feature documentation.
Sink Configuration
Optionally send Job results to external systems using sinks. Intuned supports webhook and S3 destinations. See the Sinks API reference for detailed configuration options and output formats. here are sample sink configurations: Webhook Sink:Usage
Creating a Job
Navigate to Jobs
Open your Project in the Intuned dashboard and click the “Jobs” tab.
Create New Job
Click “Create Job” to open the configuration editor. A JSON editor will appear where you can define your Job configuration.
Define Basic Info
Set a unique The Job ID must be unique within your Project and cannot be changed after creation.
id for your Job. This identifier will be used to reference the Job in API calls and the UI.Add Payload Items
Specify which APIs to run and their parameters in the Each payload item creates a separate Run when the Job executes. You can include the same API multiple times with different parameters.
payload array.Configure Execution
Set retry policies and concurrency limits in the These settings apply to all payload items unless overridden at the payload level.
configuration object.Add Schedule (Optional)
Configure intervals or calendars if you want automatic execution.Without a schedule, the Job can only be triggered manually.
Configure Sink (Optional)
Add webhook or S3 destination for results.Sinks automatically deliver results to external systems after each JobRun completes.
Configure Auth Session (Optional)
For authenticated Projects, specify an AuthSession for authenticated API calls.All Runs in the JobRun will use this same AuthSession.
Save
Click “Create” or “Save” to create your Job. Your Job is now ready to be triggered manually or will execute automatically based on the schedule.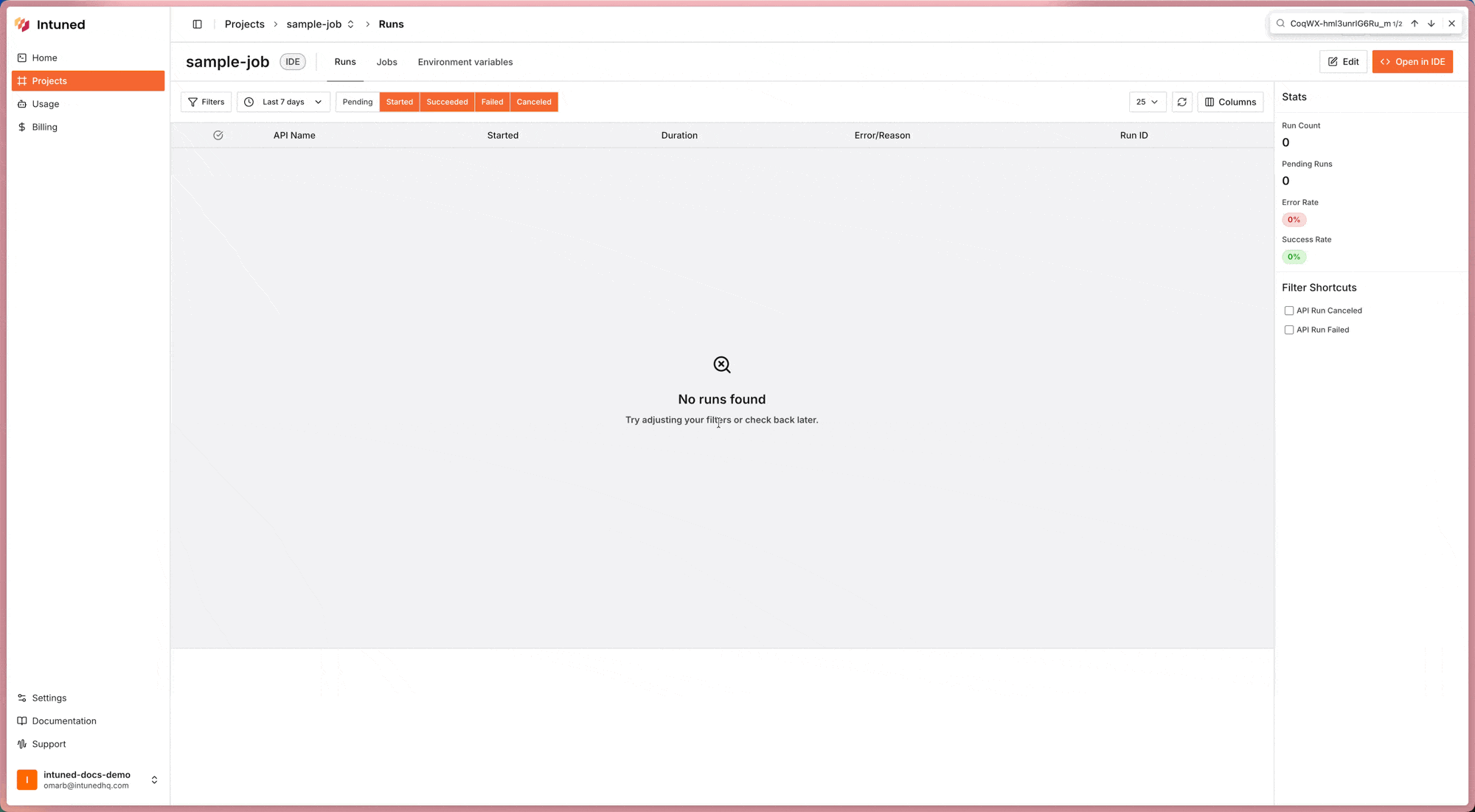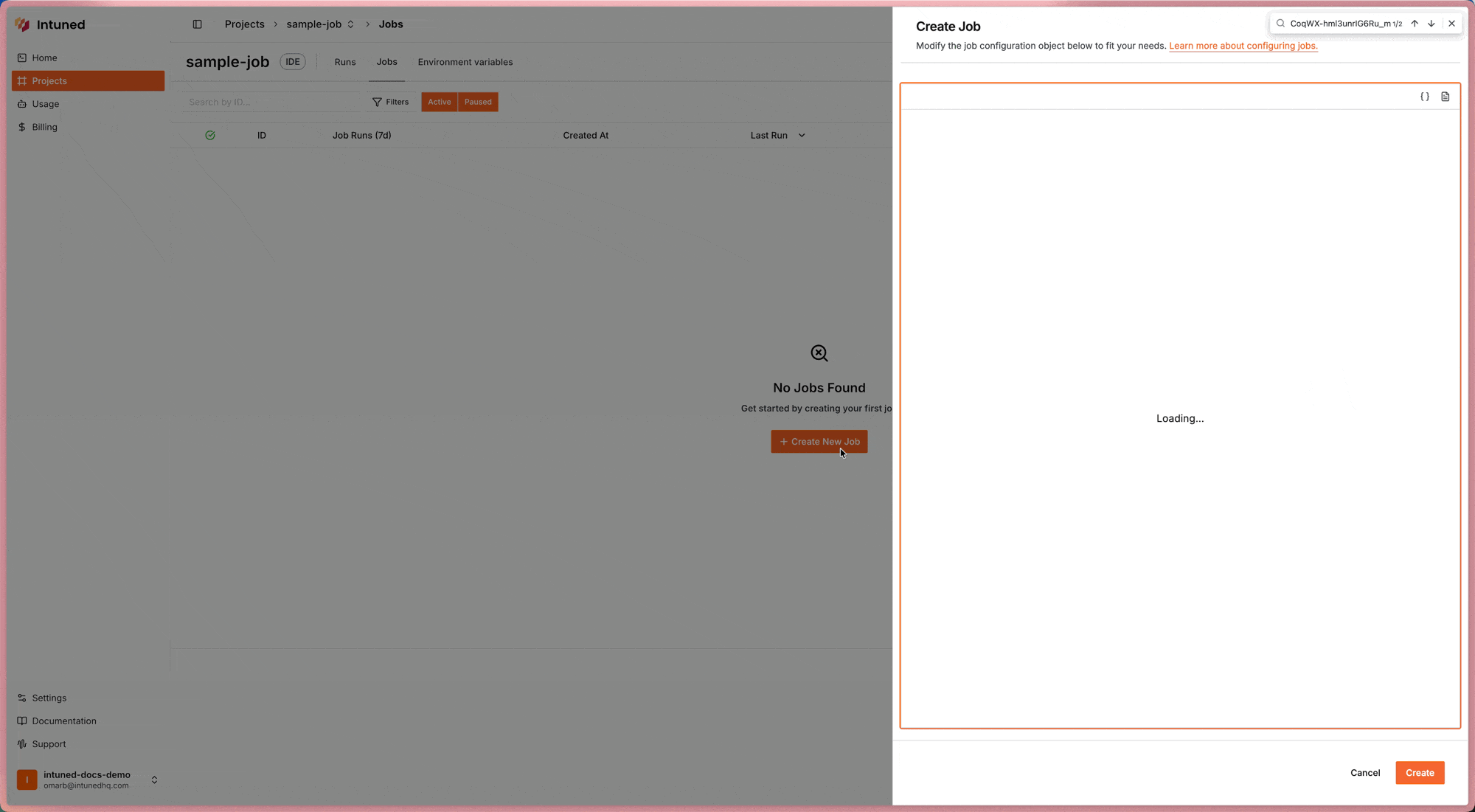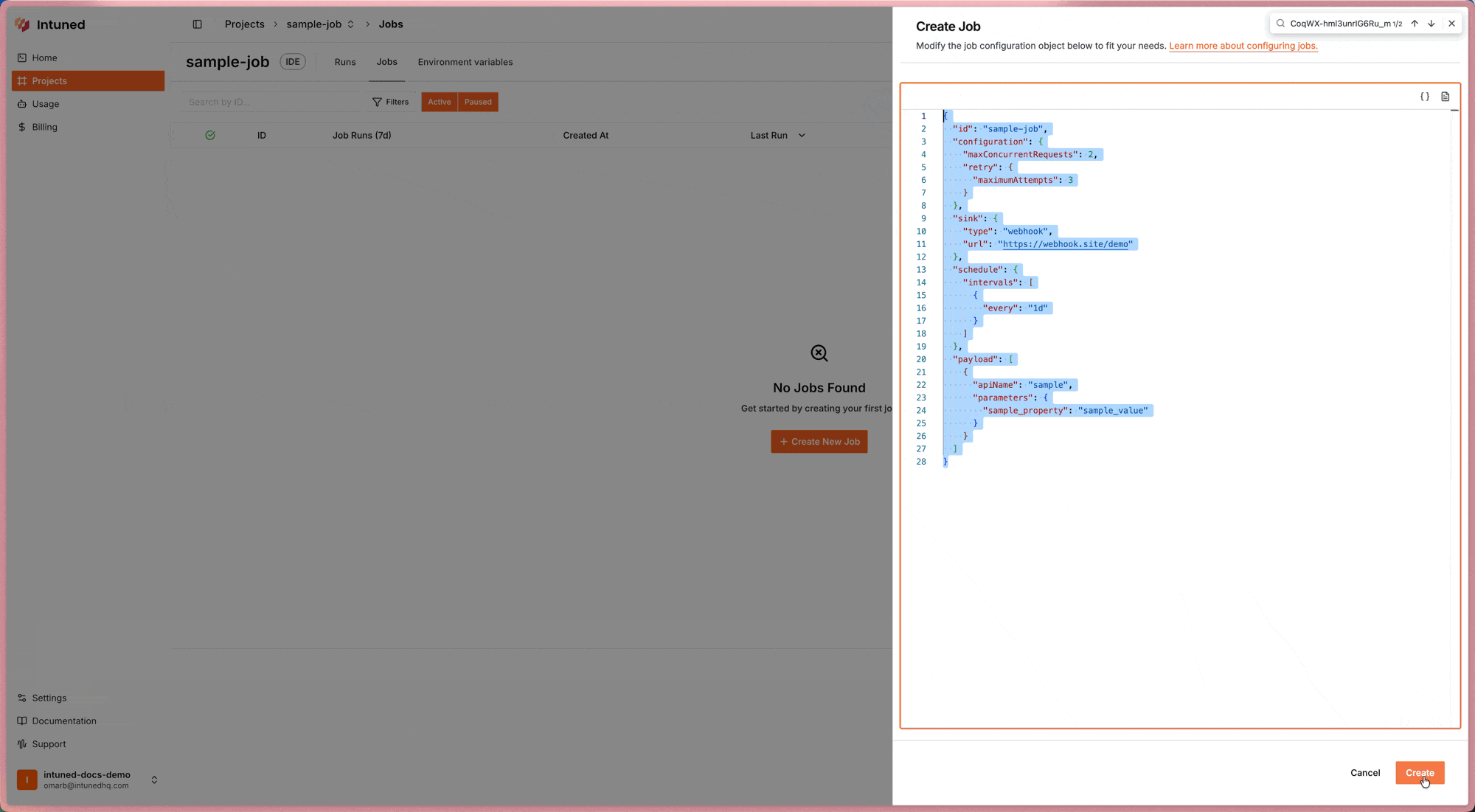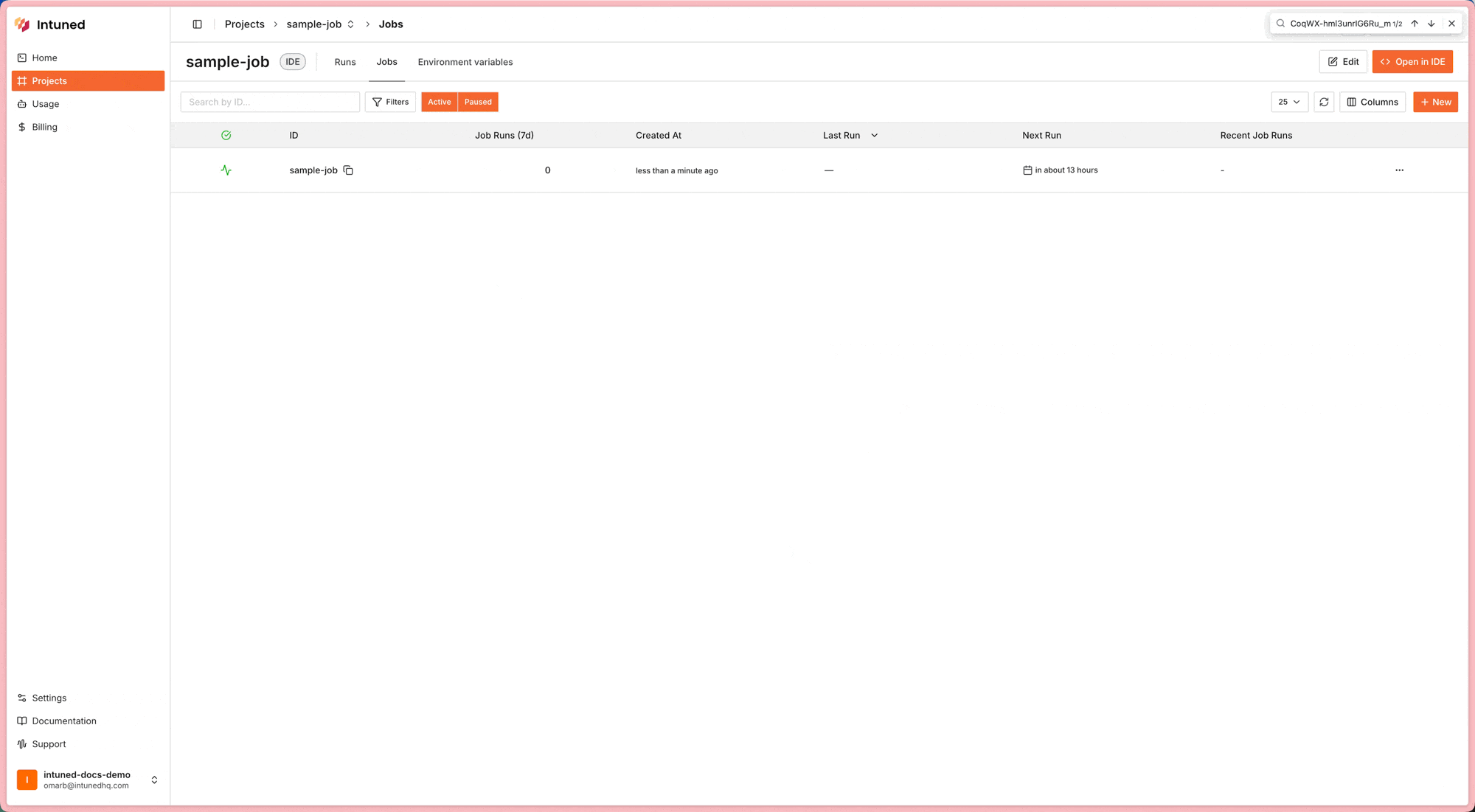
You can also programmatically create Jobs using the Create Job API endpoint.
Monitoring JobRuns
Each JobRun provides real-time visibility into execution progress:- Access JobRun Details: Click on a JobRun from the Jobs tab to view its status
- Track Progress: See how many payload items are pending, running, completed, or failed
- View Individual Runs: Expand to see details of each API execution within the JobRun
- Check Attempt Details: For any Run, view all Attempts including browser traces and logs
- Export Results: Once the JobRun completes, export aggregated results as JSON
Managing Job Lifecycle
Triggering a Job Manually: Jobs can be triggered on-demand regardless of their schedule, to trigger a Job manually:- Navigate to the Jobs tab in your Project
- Find your Job in the list
- Click the ”…” button next to the Job and select “Trigger”
- A new JobRun will start immediately
- Navigate to the Jobs tab in your Project
- Find your Job in the list
- Click the ”…” button next to the Job and select “Pause”
- Stop new JobRuns from starting (either manually or by schedule)
- Prevent in-progress JobRuns from executing new payload items and pause them. Currently running payloads will be canceled and retried again when you resume the job.
- Navigate to the Jobs tab in your Project
- Find your Job in the list
- Click the ”…” button next to the Job and select “Resume”
- Re-enables scheduling.
- Resume any paused JobRuns, allowing them to continue processing remaining payload items.
- Navigate to the Jobs tab in your Project
- Click on Job that has active JobRuns
- Click the ”…” button next to the active JobRun and select “Terminate”
- Immediately stops a specific JobRun instance.
- All in-progress Runs will be canceled, and no further payload items will be executed.
Extending run timeout
each job hasrequestTimeout configuration that control how long each Run attempt can take before it is considered failed and retried (if retries are remaining). The default value is 600 seconds (10 minutes) but some times you may want to increase this based on the expected duration of your automations. For example, if you have a Job that scrapes large reports that may take up to 30 minutes to load and process. in your api you can call extendTimeout function to reset the timeout for the current attempt. for example:
Implementing Nested Scheduling
To dynamically expand a JobRun’s payload from within an API:extendPayloadonly works within JobRuns (not standalone Runs)- Extended payload items are added to the same JobRun and tracked together
- Extended items respect the Job’s retry and concurrency configuration
- You can call
extendPayloadmultiple times within a single API execution
Working with Authenticated Jobs
For Projects with authentication enabled, all JobRuns automatically handle AuthSession validation: Creating an Authenticated Job:- Ensure you have an AuthSession created for your Project (see AuthSessions documentation)
- Include the
auth_sessionconfiguration in your Job definition - All Runs within JobRuns will automatically use this AuthSession
- All Runs in a JobRun share the same AuthSession
- In case the session became invalid and recreation also failed , Job will be paused to prevent further failed attempts and the user need to take action either by resuming the job if it was temporary issue on target website or updating the AuthSession if it was due to credential changes.
Best Practices
- Keep APIs focused: Design each API to handle a single concern. Use Jobs to orchestrate multiple APIs rather than building monolithic automations. This improves retry efficiency and debugging.
-
Use nested scheduling for discovery patterns: When you need to scrape lists before details, use one API to discover items and
extendPayloadto process each item. This keeps the architecture clean and provides granular retry control and concurrency management. -
Limit concurrency for rate-limited targets: If scraping sites with rate limits, set
maximumConcurrentRequeststo a conservative value (1-5). For robust targets, increase concurrency to improve throughput. -
Include operation metadata in payload parameters: Pass identifiers, timestamps, or context in parameters to make debugging and result correlation easier. Example:
{ "category": "electronics", "batchId": "2024-10-16" }. - Use sinks for production workflows: Configure webhooks or S3 sinks to automatically capture results rather than manually exporting. This enables automated downstream processing and creates an audit trail.
- Test Jobs manually before scheduling: for each job we recommened to create two instance of it one for QA where you can trigger it manually and verify the results without adding a schedule or sink to it and the second instance of the job has the schedule and sink configured for production use. this helps you to test and verify the job without affecting the production job.
- Monitor JobRun history regularly: Check for patterns in failures. Consistent failures in specific payload items may indicate API issues.
- Use service account AuthSessions for Jobs: When running Jobs that scrape or automate tasks, use a dedicated service account AuthSession rather than personal accounts. This prevents disruptions from personal credential changes and provides clearer audit trails.
Limitations
- Execution order is not guaranteed: Payload items within a JobRun may execute in any order, depending on concurrency settings and worker availability. Don’t rely on execution sequence.
-
Extended payload items execute asynchronously: When using
extendPayload, newly added items are queued and execute as workers become available. They don’t execute immediately or in a specific order. - No conditional execution within Jobs: Jobs execute all payload items. You cannot define conditional logic like “run API B only if API A succeeds” within the Job definition. Use nested scheduling and API-level logic for conditional workflows.
- Schedule precision: Scheduled JobRuns trigger within a reasonable window of the scheduled time but are not guaranteed to execute at the exact millisecond. For critical timing requirements, use external schedulers to trigger Jobs via API.
- Sink delivery is at-least-once: Results sent to sinks may be delivered multiple times in rare failure scenarios. Ensure your webhook or processing logic handles duplicate deliveries idempotently.
- AuthSession is shared across all Runs: All Runs in a JobRun use the same AuthSession. You cannot use different AuthSessions for different payload items within the same JobRun. If you need to run automations with multiple user accounts, create separate Jobs for each account.
- Only Credential-based authSessions support auto-recreation: If your Job uses an AuthSession created via the Recorder method, it cannot auto-recreate. You must manually recreate the AuthSession when it expires.
FAQs
What's the difference between Jobs and direct Run API calls?
What's the difference between Jobs and direct Run API calls?
Direct Run API calls execute a single API with specific parameters immediately. Jobs orchestrate multiple API calls together, provide scheduling, handle retries, manage concurrency. Use direct Runs for one-off executions; use Jobs for batch processing and recurring automations.
Can I modify a Job's payload after creating it?
Can I modify a Job's payload after creating it?
Yes, you can update Job configurations including payload at any time through the UI or API. Changes apply to future JobRuns - they don’t affect JobRuns currently in progress.
How do I pass different parameters to the same API multiple times?
How do I pass different parameters to the same API multiple times?
Include multiple payload items with the same
api value but different parameters. Each payload item creates a separate Run with its own parameter set. This is common for bulk operations like scraping multiple URLs or processing a list of accounts.What happens if my API calls extendPayload multiple times?
What happens if my API calls extendPayload multiple times?
Each call to
extendPayload adds items to the current JobRun’s queue. You can call it as many times as needed within a single API execution. All extended items are tracked together and execute according to the Job’s concurrency and retry settings.Can I use different AuthSessions for different APIs in the same Job?
Can I use different AuthSessions for different APIs in the same Job?
No, all Runs within a single JobRun use the same AuthSession specified in the Job configuration. If you need to automate tasks with multiple user accounts or different authentication contexts, create separate Jobs - one for each AuthSession. This is a deliberate design choice to ensure consistent authentication state throughout a JobRun’s execution.
How does authentication work with nested scheduling?
How does authentication work with nested scheduling?
When you use
extendPayload to add new APIs to a JobRun, all extended Runs automatically inherit the same AuthSession used by the JobRun. You don’t need to specify authentication for extended payload items - the Job-level AuthSession applies to all Runs, whether they were defined in the original payload or added dynamically. This ensures consistent authentication throughout the entire nested workflow.Related Resources
- AuthSessions Feature Documentation - Comprehensive guide to authenticated browser automations, authentication patterns, and AuthSession management
- Authenticated Browser Automations: Conceptual Guide - Deep dive into authentication concepts, lifecycle, and dependency model
- Core Concepts: Jobs - Understanding Jobs in the context of Intuned’s execution model
- Jobs API Reference - Complete API documentation for programmatic Job management
- Sinks API Reference - Detailed configuration for webhook and S3 result delivery
- Building Your First Web Scraper Tutorial - Step-by-step guide that includes Job creation and usage examples